Maschinelles Lernen mit Licht beschleunigen
Informationen sehr viel schneller und parallel verarbeiten
Im Digital-Zeitalter wachsen Datenmengen exponentiell. Besonders die Anforderungen von Muster- und Spracherkennungen oder dem autonomen Fahren übersteigen oftmals die Kapazitäten herkömmlicher Computer-Prozessoren. Wissenschaftler der Westfälischen Wilhelms-Universität Münster (WWU) entwickeln in Zusammenarbeit mit einem internationalen Forscherteam neue Ansätze und Prozessor-Architekturen, die diesen Aufgaben gewachsen sind. Nun fanden sie heraus, dass sogenannte photonische Prozessoren, bei denen Daten mittels Licht transportiert werden, Informationen sehr viel schneller und parallel verarbeiten als elektronische Chips. Die Ergebnisse sind in der Fachzeitschrift „Nature“ veröffentlicht.
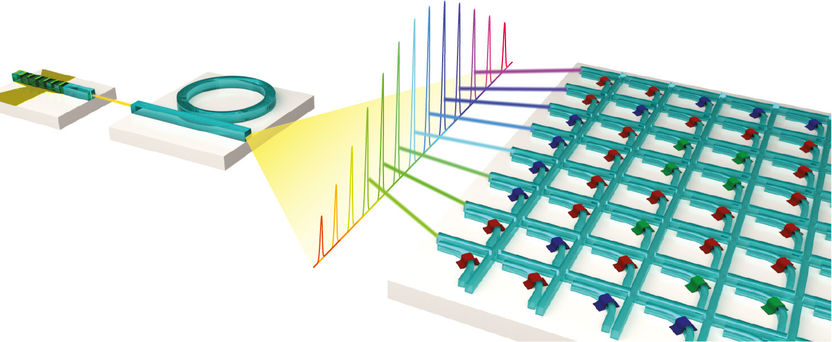
Schematische Darstellung eines Prozessors für Matrixmultiplikationen, der mit Licht arbeitet. Die Wellenleiterkreuzungsstruktur ermöglicht zusammen mit einem optischen Frequenzkamm hochparallele Datenverarbeitung.
Copyright: WWU/AG Pernice
Hintergrund und Methodik
Lichtbasierte Prozessoren zur Beschleunigung von Aufgaben im Bereich des maschinellen Lernens erlauben komplexe Rechenaufgaben mit enorm hohen Geschwindigkeiten (10¹² -10¹⁵ Operationen pro Sekunde – also eine Billion bis eine Billarde) zu verarbeiten. Herkömmliche Chips, wie zum Beispiel Grafikkarten oder spezielle Hardware wie die TPU (Tensor Processing Unit) von Google basieren auf einer elektronischen Datenübertragung und sind wesentlich langsamer. Das Forscherteam um Prof. Dr. Wolfram Pernice vom Physikalischen Institut und dem Center for Soft Nanoscience der WWU implementierte einen Hardwarebeschleuniger für sogenannte Matrixmultiplikationen, die die Hauptrechenlast in der Berechnung von neuronalen Netzen darstellen. Neuronale Netze sind eine Reihe von Algorithmen, die das menschliche Gehirn nachahmen. Das ist beispielsweise hilfreich für Objektklassifizierungen in Bildern oder der Spracherkennung.
Die Wissenschaftler kombinierten die photonischen Strukturen mit Phasenwechselmaterialien (PWMs) als energieeffiziente Speicherelemente. PWMs werden üblicherweise in der optischen Datenspeicherung mit DVDs oder Blu-Rays eingesetzt. Im vorgestellten Prozessor ermöglicht dies die Speicherung und den Erhalt der Matrixelemente, ohne die Notwendigkeit Energie zuzuführen. Als Lichtquelle nutzten die münsterschen Physiker einen chip-basierten Frequenzkamm. Ein Frequenzkamm bietet verschiedene optische Wellenlängen, die unabhängig voneinander im selben System verarbeitet werden. Dadurch ergibt sich eine parallele Datenverarbeitung; auch Wellenlängenmultiplexverfahren genannt. „Unsere Studie ist die erste, die Frequenzkämme im Bereich der künstlich neuronalen Netze anwendet“, sagt Wolfram Pernice.
Im Experiment verwendeten die Physiker ein „Convolutional Neural Network“ (zu Deutsch: faltendes neuronales Netzwerk) zur Erkennung handgeschriebener Ziffern. Bei diesen Netzwerken handelt es sich um ein von biologischen Prozessen inspiriertes Konzept im Bereich des maschinellen Lernens. Anwendung finden sie vor allem bei der Verarbeitung von Bild- oder Audiodaten, da sie aktuell die höchsten Klassifizierungsgenauigkeiten erreichen. „Die Faltungsoperation zwischen Eingangsdaten und einem oder mehreren Filtern, die zum Beispiel eine Hervorhebung von Kanten in einem Bild sein kann, lässt sich sehr gut auf unsere Matrixarchitektur übertragen. Das Ausnutzen von Licht für die Signalübertragung erlaubt dem Prozessor eine parallele Datenverarbeitung durch Wellenlängenmultiplexen, die zu einer höheren Rechendichte führt. Dabei werden viele Matrixmultiplikationen in nur einem Zeitschritt durchgeführt. Anders als bei herkömmlicher Elektronik, die üblicherweise im niedrigen Gigahertz-Bereich arbeitet, können optisch Modulationsgeschwindigkeiten im Bereich von 50 bis 100 Gigahertz realisiert werden“, erklärt Johannes Feldmann, Erstautor der Studie. Das Verfahren ermöglicht somit bisher unerreichte Datenraten und Rechendichten, also Operationen pro Prozessorfläche.
Die Ergebnisse sind vielfältig einsetzbar: Im Bereich der künstlichen Intelligenz können mehr Daten zeitgleich und energieeffizient verarbeitet werden. Der Einsatz von größeren neuronalen Netzen erlaubt zudem genauere und bisher unerreichte Vorhersagen sowie präzisere Datenanalysen. Beispielsweise unterstützen photonische Prozessoren die Auswertung großer Datenmengen in der medizinischen Diagnostik, etwa bei hochaufgelösten 3D-Daten spezieller Bildgebungsverfahren. Weitere Anwendungsgebiete sind zum anderen das autonome Fahren, das auf eine schnelle und genaue Auswertung der Sensordaten angewiesen ist, sowie IT-Infrastrukturen wie „Cloud Computing“, die unter anderem Speicherplatz, Rechenleistung oder Anwendungssoftware bereitstellen.
Originalveröffentlichung
Johannes Feldmann, Nathan Youngblood, Maxim Karpov, Helge Gehring, Xuan Li, Maik Stappers, Manuel Le Gallo, Xin Fu, Anton Lukashchuk, Arslan Raja, Junqiu Liu, David Wright, Abu Sebastian, Tobias Kippenberg, Wolfram Pernice, and Harish Bhaskaran; "Parallel convolution processing using an integrated photonic tensor core"; Nature; 2021

Weitere News aus dem Ressort Wissenschaft





























































